Introduction to efficient data systems
Self-link: intro-data-system.xiangpeng.systems
Efficient =
efficient storage
+ efficient
compute
Question 1
What's the average grade?
Data
What's the average grade?
Option 1: Store as JSON
[
{
"id": 1001,
"name": "Alice Johnson",
"grade": 85,
"subject": "Computer Science",
"enrollmentDate": "2024-09-01"
},
{
"id": 1002,
"name": "Bob Smith",
"grade": 92,
"subject": "Computer Science",
"enrollmentDate": "2024-09-01"
},
{
"id": 1003,
"name": "Carol Davis",
"grade": 78,
"subject": "Computer Science",
"enrollmentDate": "2024-09-02"
},
{
"id": 1004,
"name": "David Wilson",
"grade": 88,
"subject": "Mathematics",
"enrollmentDate": "2024-09-02"
},
{
"id": 1005,
"name": "Emma Brown",
"grade": 95,
"subject": "Mathematics",
"enrollmentDate": "2024-09-03"
}
]
How many bytes of data do we have?
~200 bytes
How many bytes do we store?
~436 bytes
Repetitive column names!
What's the average grade?
Option 2: Store as CSV
ID,Name,Grade,Subject,Enrollment Date
1001,Alice Johnson,85,Computer Science,2024-09-01
1002,Bob Smith,92,Computer Science,2024-09-01
1003,Carol Davis,78,Computer Science,2024-09-02
1004,David Wilson,88,Mathematics,2024-09-02
1005,Emma Brown,95,Mathematics,2024-09-03How many bytes do we read?
~238 bytes
(entire CSV file)
How many bytes do we use?
20 bytes
(only grade column)
Read unused data!
What's the average grade?
Option 3:
YAFF-V0
💡 Yet Another File Format, version 0
ID: 1001,1002,1003,1004,1005
Name: Alice Johnson,Bob Smith,Carol Davis,David Wilson,Emma Brown
Grade: 85,92,78,88,95
Subject: Computer Science,Computer Science,Computer Science,Mathematics,Mathematics
Enrollment Date: 2024-09-01,2024-09-01,2024-09-02,2024-09-02,2024-09-03How many bytes do we read?
118 bytes
(ID to Grade column)
How to only read grade column?
Needs metadata!
What's the average grade?
YAFF-V1
1001,1002,1003,1004,1005
Alice Johnson,Bob Smith,Carol Davis,David Wilson,Emma Brown
85,92,78,88,95
Computer Science,Computer Science,Computer Science,Mathematics,Mathematics
2024-09-01,2024-09-01,2024-09-02,2024-09-02,2024-09-03
id:1; name:2; grade:3; subject:4; enrollmentDate:5- Read metadata (usually small!)
- Read selected range
Achievement: read only we need!
Checkpoint 1: row store vs column store
Row store
ID,Name,Grade,Subject,Enrollment Date
1001,Alice Johnson,85,Computer Science,2024-09-01
1002,Bob Smith,92,Computer Science,2024-09-01
1003,Carol Davis,78,Computer Science,2024-09-02
1004,David Wilson,88,Mathematics,2024-09-02
1005,Emma Brown,95,Mathematics,2024-09-03Column store
1001,1002,1003,1004,1005
Alice Johnson,Bob Smith,Carol Davis,David Wilson,Emma Brown
85,92,78,88,95
Computer Science,Computer Science,Computer Science,Mathematics,Mathematics
2024-09-01,2024-09-01,2024-09-02,2024-09-02,2024-09-03
id:1; name:2; grade:3; subject:4; enrollmentDate:5CSV
JSON
MySQL
PostgreSQL
SQL server
Parquet
ORC
Arrow
DuckDB
DataFusion
What are the pros and cons?
hint: how to add a row?
Question 2
What's the average grade that are larger than 85?
Data
What's the average grade that are larger than 85?
Option 1: YAFF-V1
2001,2002,2003,2004,2005,2006,2007,2008,2009,2010
Jake Miller,Sophie Chen,Marcus Rodriguez,Luna Park,Ethan Thompson,Maya Patel,Oliver Kim,Isabella Garcia,Noah Williams,Zara Ahmed
63,67,72,75,79,82,84,89,93,97
Physics,Chemistry,Biology,Computer Science,Mathematics,Physics,Chemistry,Biology,Computer Science,Mathematics
2024-09-05,2024-09-06,2024-09-07,2024-09-08,2024-09-09,2024-09-10,2024-09-11,2024-09-12,2024-09-13,2024-09-14
id:1; name:2; grade:3; subject:4; enrollmentDate:5- Read metadata (usually small!)
- Read selected range
How to do better?
Data is (roughly) sorted/clustered:
63,67,72,75,79,82,84,89,93,97
What's the average grade that are larger than 85?
YAFF-V2
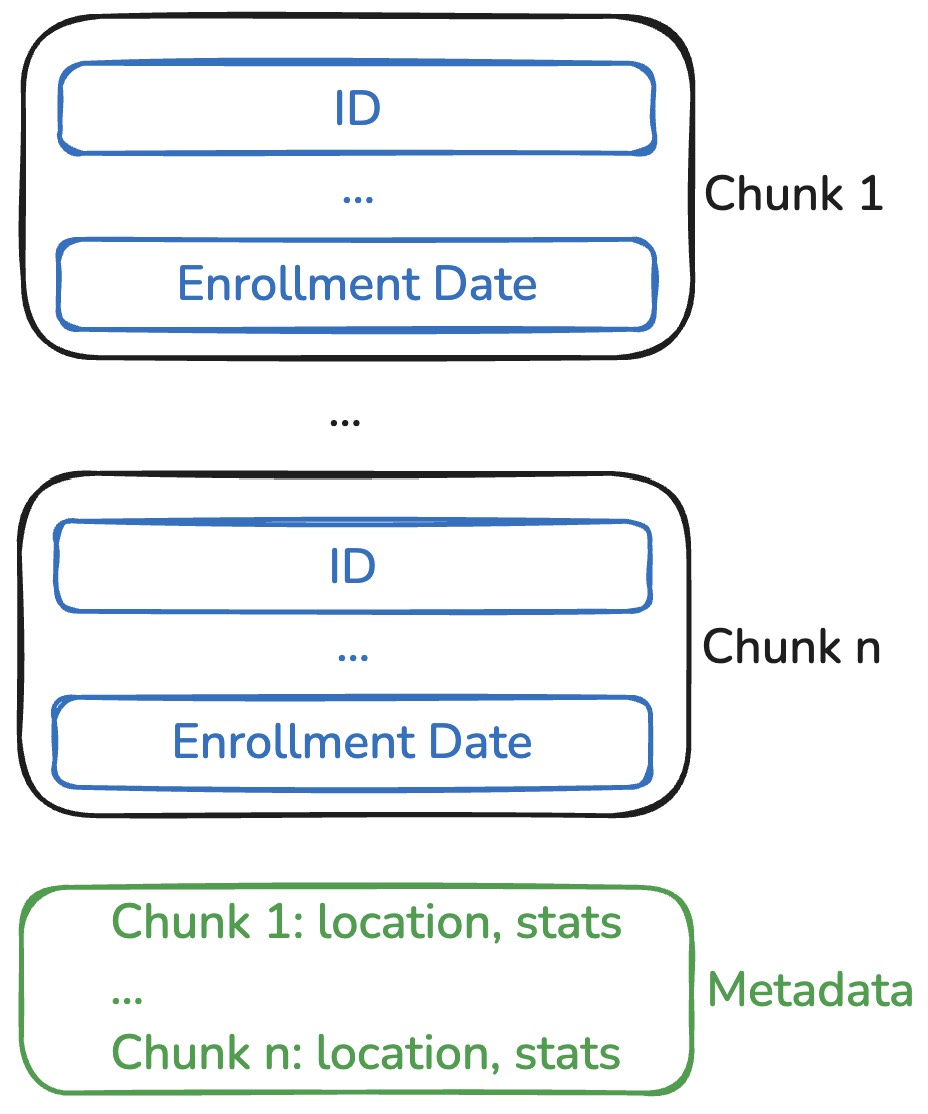
63,67,72,75,79 | min: 63, max: 79
82,84,89,93,97 | min: 82, max: 97- Chunk the data, each chunk (e.g., 5 rows) maintains its min and max values.
- If a chunk's max value is smaller than 85, skip the chunk entirely.
What's the average grade that are larger than 85?
YAFF-V2 (example)
What's the average grade that are larger than 85?
YAFF-V2: chunks + statistics
Checkpoint 2: Static pruning
Key idea: prune data using pre-computed
statistics
Zone map
(min/max/null count)
Filter
(Bloom filter, range filter, etc.)
Index
(B-tree, Hashtable, LSM-tree, etc.)
Question 3
Read all Subjects!
Data
Read all Subjects!
YAFF-V2
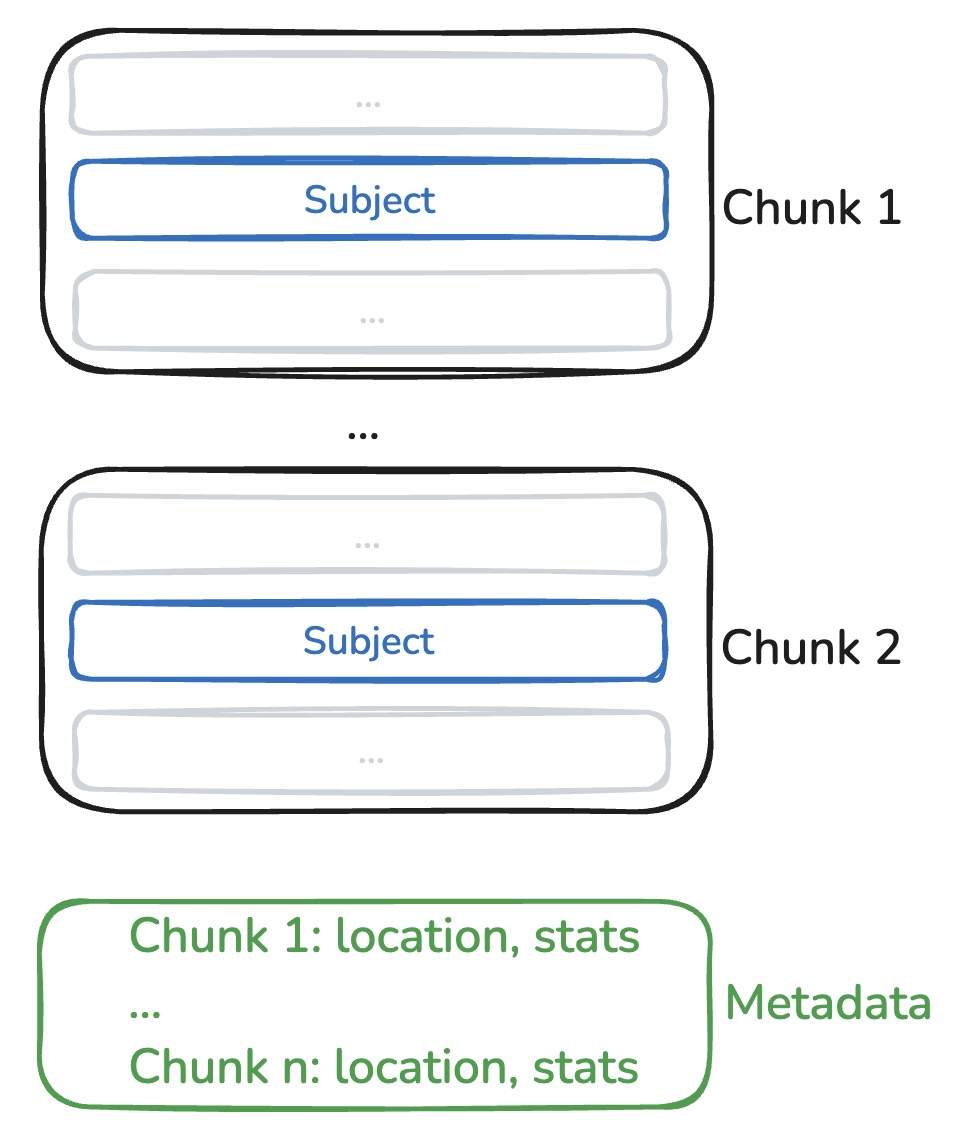
How many bytes do we read?
Can you do better?
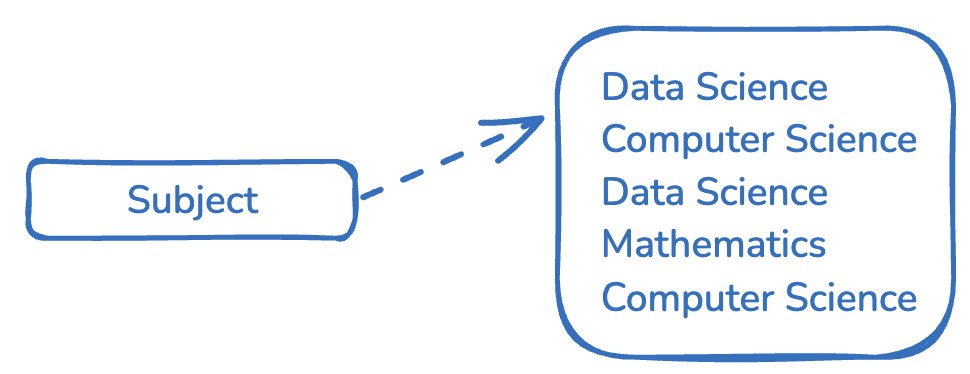
Hint: how many strings are unique?
Read all Subjects!
YAFF-V3

- Key idea: replace full strings with symbols.
- Store the symbols (dictionary) in the metadata.
Less data to read -> faster
Read all Subjects!
YAFF-V3 (+compression)
→
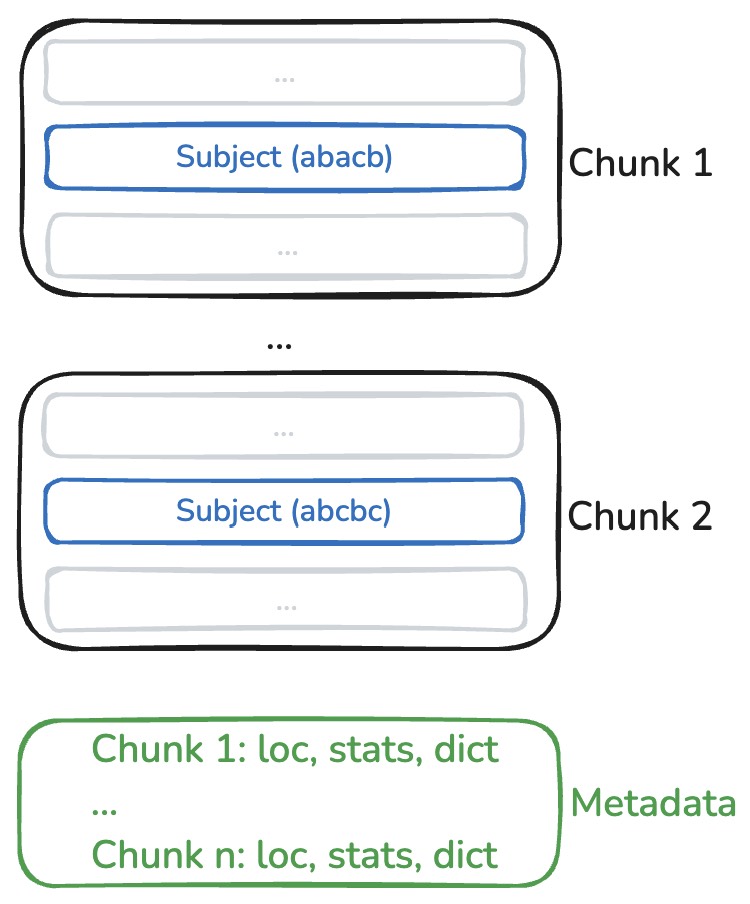
- Each column is "dictionary-encoded"
- Dictionary is stored in the metadata
Checkpoint 3: Big data needs compression
Key idea: most data has low entropy
General purpose compression
(Bytes in, bytes out)
Snappy, LZ4, ZSTD, etc.
Type-specific compression
(Datatype-dependent compression)
Delta encoding, Run-length encoding, etc.
Question 4
List all names whose grade are larger than 85!
Data
List all names whose grade are larger than 85!
Option 1: read then filter
Step 1: Read both columns
Jake Miller,Sophie Chen,Marcus Rodriguez,Luna Park,Ethan Thompson,Maya Patel,Oliver Kim,Isabella Garcia,Noah Williams,Zara Ahmed63,67,72,75,79,82,84,89,93,97Step 2: Filter grade > 85
Isabella Garcia,Noah Williams,Zara AhmedCan you do better?
List all names whose grade are larger than 85!
Option 2:
read -> filter -> read
Step 1: Read Grade
63,67,72,75,79,82,84,89,93,97Step 2: Filter grade > 85
00000_10011Step 3: Read Name
Isabella Garcia,Noah Williams,Zara AhmedCheckpoint 4: dynamic pruning
Key idea: prune data based on what we already read
Filter pushdown
Aggregation pushdown
Dynamic filtering
Side-way information passing
Summary
-
Row store vs Column store
→ Write-optimized vs Read-optimized
-
Static pruning
→ Prune data using pre-computed statistics
-
Compression
→ Most data has low entropy
-
Dynamic pruning
→ Prune data based on what we already read
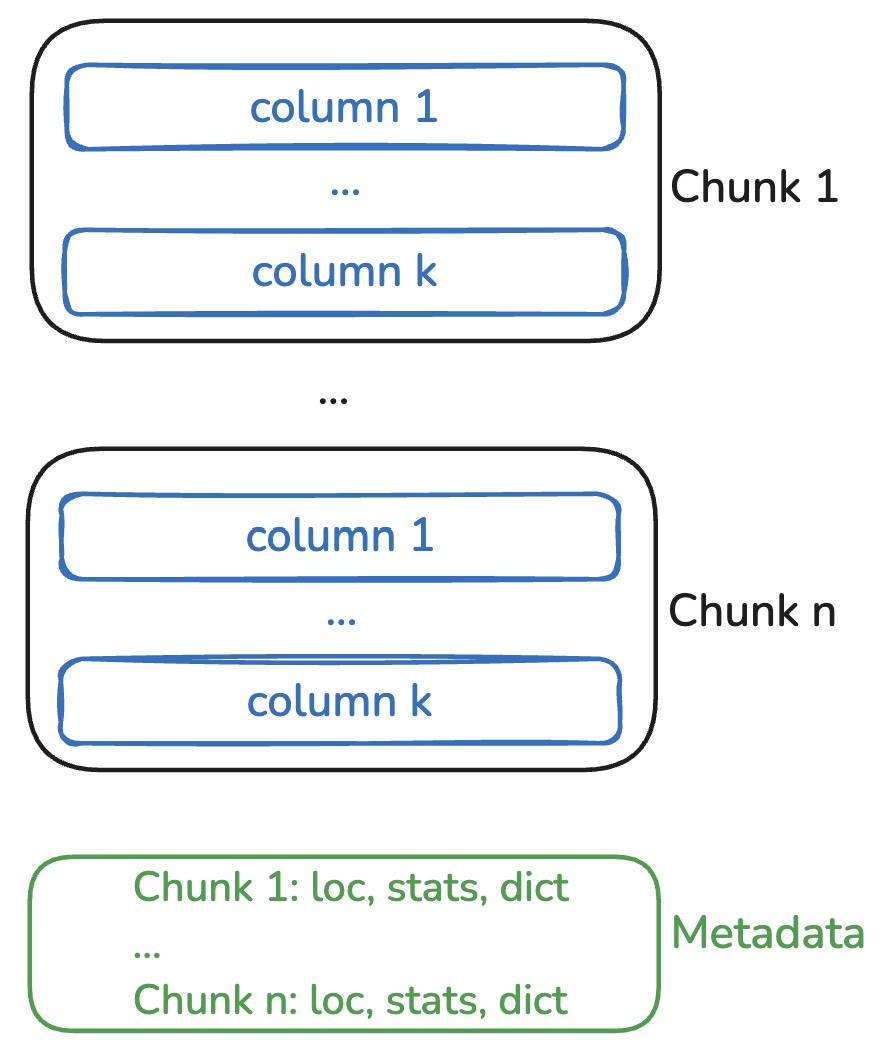
Efficient data system: a beautiful new world!

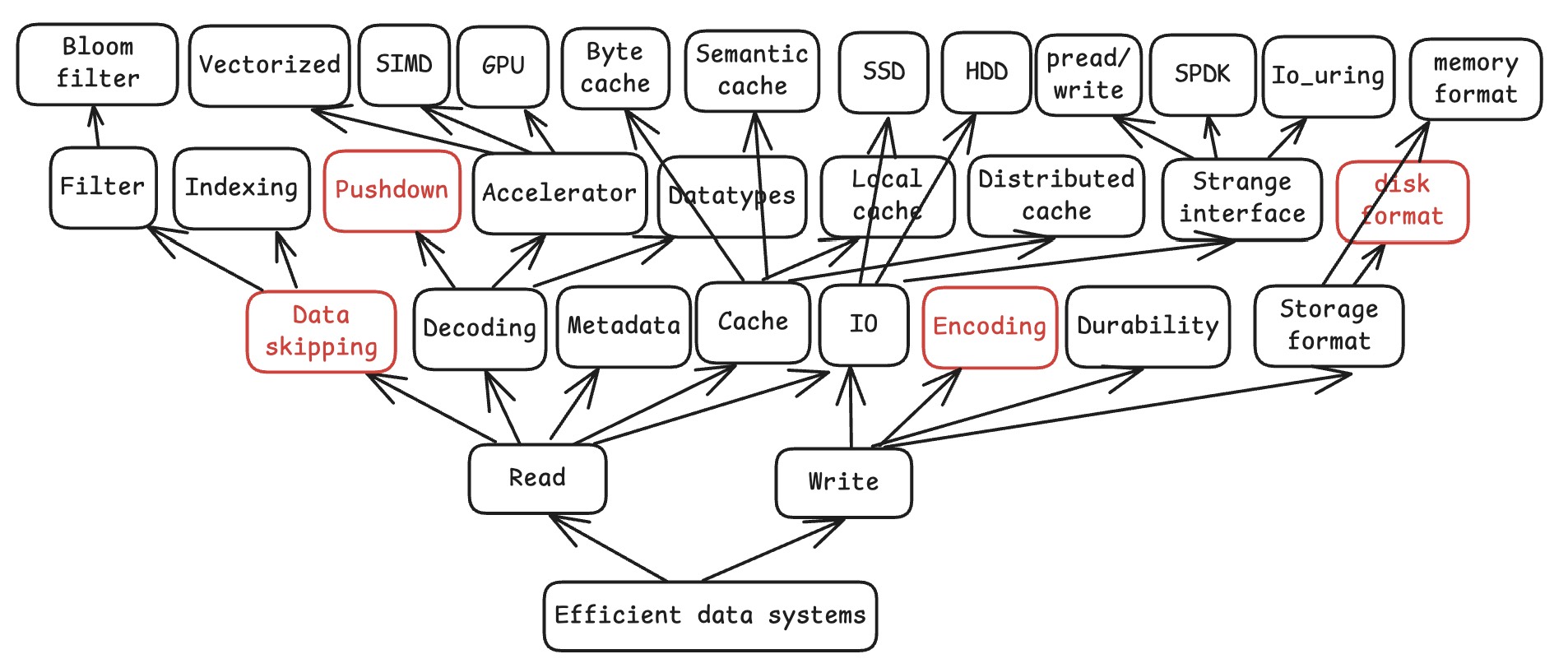
* Red boxed topics are briefly covered in this lecture.